Novichkov, PS*; Chandonia, J-M*; Arkin, AP. (2022) CORAL: A framework for rigorous self-validated data modeling and integrative, reproducible data analysis. GigaScience [DOI]:10.1093/gigascience/giac089 OSTI ID: 1888047
The Contextual Ontology-based Repository Analysis Library (CORAL) platform greatly facilitates adherence to the FAIR principles, including the especially difficult challenge of making heterogeneous datasets Interoperable and Reusable across all parts of a large, long-lasting organization such as ENIGMA.
We introduce a novel approach to modeling quantitative data: mathematical data structures are extensively labeled with contextual information, such as what is being measured and the units of measurement, using pre-defined atomic data types we call microtypes, which in turn rely heavily on ontologies. This allows data generators to easily document the hundreds of complex data types used throughout a large organization in a FAIR way.
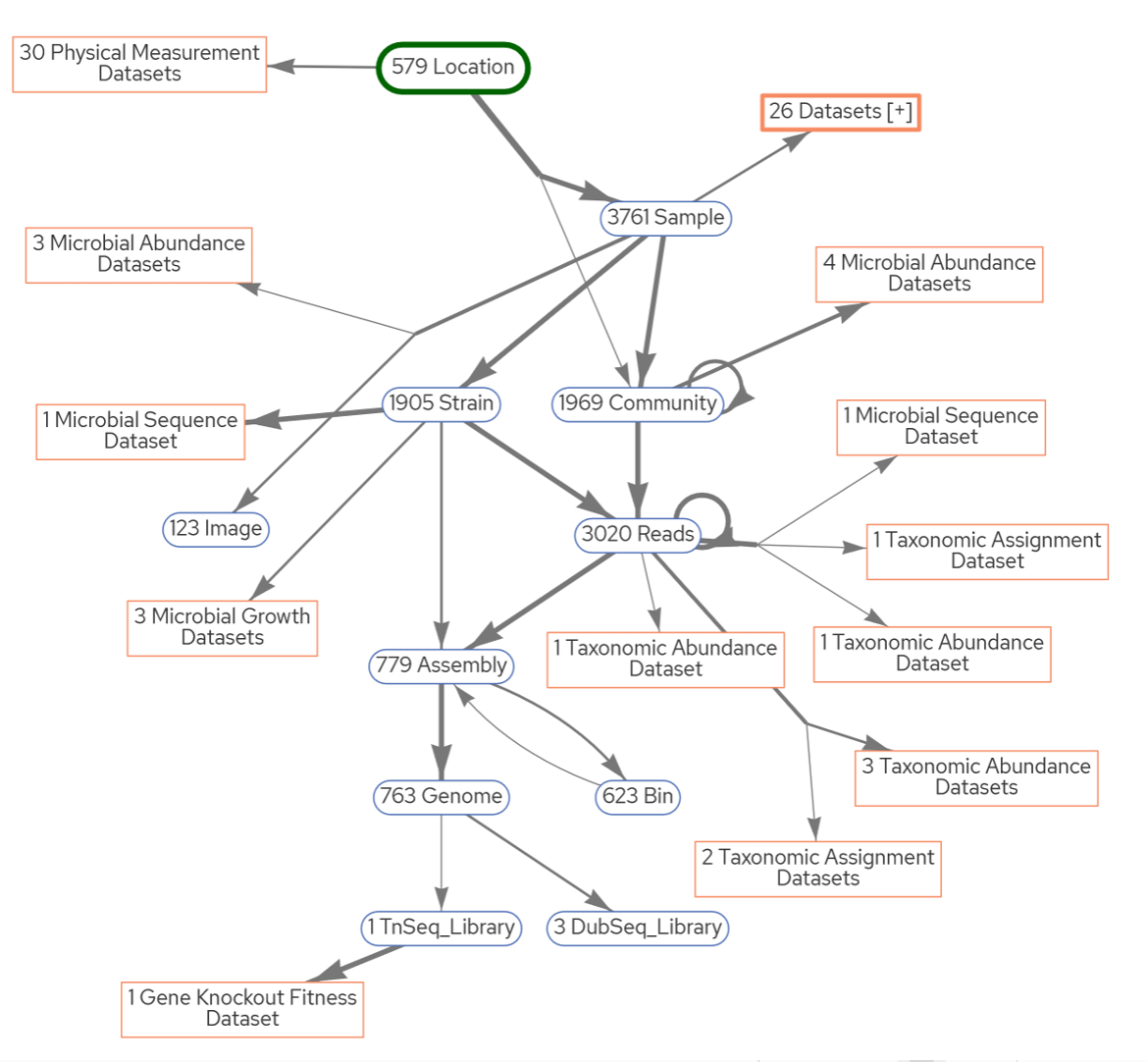
The figure on the right shows a number of these quantitative datasets (orange boxes) generated by ENIGMA that are linked to traditional data types (blue and green ovals). Edges in the graph document the processes by which one dataset is derived from another, thus annotating the provenance of all data.
In addition to the novel data model, CORAL provides a web-based front end for uploading and exploring datasets, as well as powerful data analysis in Jupyter notebooks. https://github.com/jmchandonia/CORAL